I spent a lot of time confused and in great frustration while trying to set up this model. There is a lot of information out there and a lot of it is hugely confusing. I wanted to lay down some basic principles to avoid some of the pain I experienced with this model. Below are some tips and basic clarifications that really made me understand the model and wrap my head around it.
1) There are two ways you can approach this model. One is using pacemaker and one is replacing pacemaker with resource manager. If you are using pacemaker do not start resource manager (rgmanager) even though you have to install it as a dependency to the other components. I accidentally tried to do a mixture of both and that was a big mess.
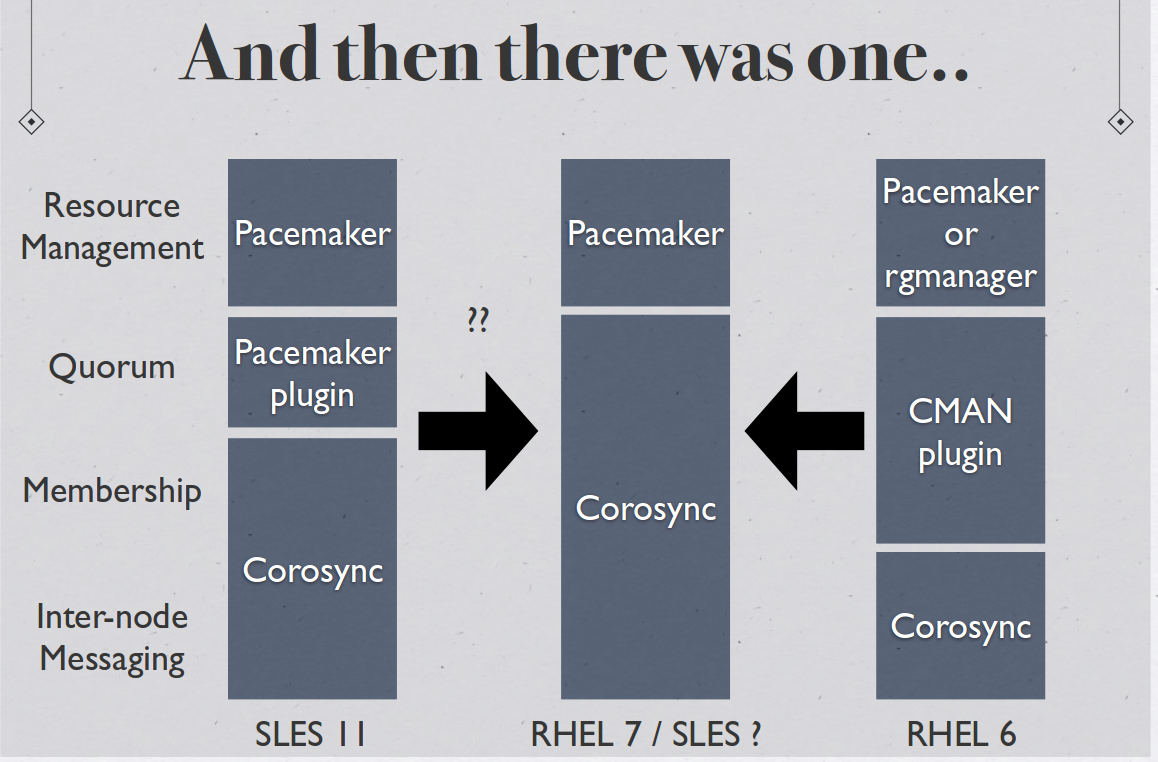
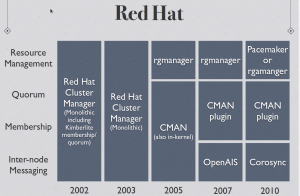
Andrew Beekhof of the pacemaker project provided me with some excellent diagrams to explain the progression of the HA Cluster for Redhat. The full pdf can be found here (https://www.dropbox.com/s/aj328jahoztv4w8/A%20Tale%20of%20Two%20Stacks.pdf):
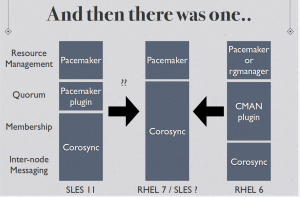
2) If you are going to use pacemaker and not rgmanager (which I understand to be the better option for now) do not put your resources in /etc/cluster/cluster.conf. They should be handled by pacemaker.
3) There are two tools for setting up pacemaker, crmsh and pcs. Pcs doesn’t do with RHEL what it does with Fedora. Pcs lacks the ability to replace the crm tool in RHEL 6. Do not attempt to use it. You will run into problems.
4) If you see you are missing the crm binary but have a lot of crm_xxx binaries this means you have not actually installed the crmsh package. Crm used to be part of the pacemaker project and is not their own project under the package of crmsh. Therefore when you download pacemaker you will automatically have the crm_xxx binaries. If you want to be able to set up pacemaker via the crm command make sure you run a yum install crmsh command or you will not have it.
5) In the pacemaker model CMAN – which is the front end for corosync in RHEL currently – handles quorum and monitors nodes. Pacemaker handles and monitors resources. Setup your resources with pacemaker using crm and setup your nodes using ccs – which is the tool for /etc/cluster/cluster.conf file. I would suggest following the RedHat quickstart guide from cluster labs to get cluster.conf file set up (http://clusterlabs.org/quickstart-redhat.html).
6) In the setup using the redhat quickstart guide to you are only deferring the handling of fencing to pacemaker. You have not set up fencing and will need to do using the crm tool to choose a device to handle the fencing. For example if you are using a couple of IBM boxes you want to use the RSA to handle fencing.
7) You can follow this guide to set up fencing (http://clusterlabs.org/doc/en-US/Pacemaker/1.1-crmsh/html/Clusters_from_Scratch/ch09.html). While to many people fencing means STONITH (shoot the other node in the head) there are other options such as plain old isolation rather than restarting them. The IPs you put into a STONITH setup are the IPs of the device handling the fencing (such as an RSA) and not the IPs of the nodes. Each management device may be different so you need to understand what each device needs in order to be given a restart command. The different options you have also depend on the device you are using. I suggest you research it carefully. If you are using an RSA you can find some options here (http://linux.die.net/man/8/fence_rsa)
8) Its best not to have chkconfig on for any cluster components. You an start the cluster using pacemaker by only starting pacemaker. By cluster components that means Corosync, CMAN, pacemaker and whatever resources your cluster are managing, in my case it was DRBD and mysql.
9) Last piece of advice I can give you, and this might be the most valuable, if you get stuck you can find a chat on irc called #linux-cluster. There are a lot of people more than happy to answer your questions for you including Andrew Beekhof (beekhof) who is the pacemaker guy. He is located in Australia so if you want to speak to him specifically you need to hang out there during his hours or leave a message for him and he will see it when he is around. That said there are over 100 people who hang out there, some of them are using clusters actively who can give you advice no matter what setup you are using. Redhat seems to be the most confusing and the guy you want to speak to for accurate information about Redhat is Anderw Beekhof. If you aren’t pressed for time they have a mailing list as well which I think they prefer. That way the information is out there for the general public.
Configuration Steps for a MySQL cluster – if you are the Linux HA cluster it for a different purpose edit per your needs:
This setup is based on LVM disk partitioning so make sure the disk is set up on the operating system install accordingly.
Download Software
both nodes> yum –y install drbd kmod-drbd
Setup LVM. The LVM partition for this scenario is named system so that the path is the same on both nodes. Also something to consider upon installation. The size to set aside needs to be chose based on the expectations for the database/s this is set up for.
both nodes> lvcreate –mysql_drbd –size=20G system
Go to the drbd directory
server1> cd /etc/drbd.d
Create the config file as seen below in the config files section. Edit it to match the necessary parameters of whatever system is being used and save.
server1> vi mysql.res
Copy it to the second node so that they are identical.
server1> scp mysql.res server2:/etc/drbd.d
Check the drbd.d directory has the global_common.conf file as well. This file contains general information for all the resources. It should come with the install. Nothing was changed until different replication types were tested. If the replication type is changed it would be in this file.
Create the drbd metadata.
Both> drbdadm create-md mysql
Reboot both boxes
Both> reboot now
start them both together. One will not start without its peer.
Both> service drbd start
Make sure everything is consistent and make one the primary. Once done a sync will occur.
server1> drbdam — –overwrite-data-of-peer primary mysql
Create the file system. If this is run this again at any other point it will wipe the existing data in the file system.
server1> mkfs.ext4 /dev/drbd0
Mount the file system to the mysql directory.
server1> mount /dev/drbd0 /var/lib/mysql
Check that it looks okay. If it does the correct amount of disk space will be applied to the directory
server1> df –h /var/lib/mysql
Output should look like
/dev/drbd0 20G usedM howmuchspaceleftG percentageinuse% /var/lib/mysql
Check all looks okay
server1> drbd-overview
Output should look like
0:mysql/0 Connected Primary/Secondary UpToDate/UpToDate A r—– /var/lib/mysql ext4 20G usedM howmuchspaceleftG percentageinuse%
Install MySQL
Both> yum –y install mysql-client mysql-server
At this point MySQL can be started and set up or have data imported to test all is well. Do not forget to shut down MySQL after testing is completed. Alternatively wait for the full setup to be completed befores setting up and starting up MySQL. Also unmounts the directory promte the primary to secondary so that the cluster resource manager can take over control of the components.
Both> yum install pacemaker cman ccs resource-agents crmsh
Create the cluster.
server1> ccs -f /etc/cluster/cluster.conf –createcluster pacemaker1
Add the nodes
server1> ccs -f /etc/cluster/cluster.conf –addnode server1
server1> ccs -f /etc/cluster/cluster.conf –addnode server2
Set fencing to defer to Pacemaker.
server1> ccs -f /etc/cluster/cluster.conf –addfencedev pcmk agent=fence_pcmk
server1> ccs -f /etc/cluster/cluster.conf –addmethod pcmk-redirect node1
server1> ccs -f /etc/cluster/cluster.conf –addmethod pcmk-redirect node2
server1> ccs -f /etc/cluster/cluster.conf –addfenceinst pcmk node1 pcmk-redirect port=node1
server1> ccs -f /etc/cluster/cluster.conf –addfenceinst pcmk node2 pcmk-redirect port=node2
Disable the need for quorum from CMAN. This will let the cluster function if only one node is up.
Both> echo “CMAN_QUORUM_TIMEOUT=0” >> /etc/sysconfig/cman
This will start everything for the Pacemaker cluster. No other components need to be started.
Both> service pacemaker start
As STONITH could not be supported it is disabled. If STONITH can be supported it is advised that it is used.
server1> pcs property set stonith-enabled=false
This will mean pacemaker will not require quorum so it can function with a single node if one dies.
server1> pcs property set no-quorum-policy=ignore
Failover after one reconnect attempt – To minimize downtime.
server1> pcs property set migration-threshold=1
I wanted the resources to stick to the box as long as things were working but to failover if a service failed to be restarted. A value of 0 would mean it always failed back and 100 would mean the box had to die to failover so it was set it to 51.
server1> pcs property set resource-stickiness=51
Set up the configurations in crm live mode.
server1> crm configure
Output:
crm(live)configure#
DRBD Resource Setup.
crm(live)configure# primitive p_drbd_mysql ocf:linbit:drbd params
drbd_resource=”mysql.res” op monitor interval=”15s”
Creating a master/slave relationship with DRBD.
crm(live)configure# ms ms_drbd_mysql p_drbd_mysql meta master-max=”1″ master-node-max=”1″ clone-max=”2″ clone-node-max=”1″ notify=”true”
The directions for mounting drbd to mysql directory as set up in the mysql.res file.
crm(live)configure# primitive p_fs_mysql ocf:heartbeat:Filesystem params device=”/dev/drbd0″ directory=”/var/lib/mysql” fstype=”ext4″
Setting up the virual IP.
crm(live)configure# primitive p_ip_mysql ocf:heartbeat:IPaddr2 params ip=”10.1.1.3″ cidr_netmask=”24″ nic=”eth0″
Setting up the MySQL instance.
crm(live)configure# primitive p_mysql ocf:heartbeat:mysql params
binary=”/usr/sbin/mysqld” config=”/etc/my.cnf” datadir=”/var/lib/mysql” pid=”/var/lib/mysql/mysql.pid” socket=”/var/lib/mysql/mysql.sock” user=”mysql” group=”mysql” additional_parameters=” –bind-address=10.1.1.3 –user=mysql” op start timeout=30s op stop timeout=30s op monitor interval=20s timeout=30s
So all the resources are handled as a group.
crm(live)configure# group g_mysql p_fs_mysql p_ip_mysql p_mysql
Make sure the mysql group created is on the same node as the drbd (ms_drbd_mysql) master.
crm(live)configure# colocation c_mysql_on_drbd inf: g_mysql ms_drbd_mysql:Master
Setting a startup order.
crm(live)configure# order o_drbd_before_mysql inf: ms_drbd_mysql:promote g_mysql:start
Save the configurations created above.
crm(live)configure# commit
Quit crm live.
crm(live)configure# quit
Make sure chkconfig is off on every service but DRBD. This means the service will not start up on when the server starts up. If it is off on Pacemaker it means the cluster will not start on startup but if a node is problematic and shut down or killed automatically putting it back into the cluster without knowing what the issue is can potentially cause more problems than automatically starting pacemaker on crash solves. RGManager and ricci have been added here because it has been installed it and it will interfere with pacemaker if it starts up.
Both>chkconfig mysql off
Both>chkconfig corosync off
Both>chkconfig cman off
Both>chkconfig rgmanager off
Both>chkconfig ricci off
Both>chkconfig pacemaker off
Both>chkconfig drbd on
- Corosync Setup (should you choose to use it INSTEAD of Pacemaker
See the config file below as, unlike Pacemaker, this one can be edited.
Start CMAN.
Both>service CMAN start
Start resource manger to manage the service.
Both> service rgmanager start
Start the service that allows resorce manager to communicate with the nodes. Best to set chkconfg ricci on as well.
Both> service ricci start
Make sure chkconfig is off on every service but DRBD and ricci. If it is off for CMAN and rgmanager it means the cluster will not start on startup but if a node is problematic and shut down or killed automatically putting it back into the cluster without knowing what the issue is can potentially cause more problems than automatically starting pacemaker on crash solves. Pacemaker is included here because it has been installed it and it will interfere with RGManager if it starts up.
Both>chkconfig mysql off
Both>chkconfig corosync off
Both>chkconfig cman off
Both>chkconfig rgmanager off
Both>chkconfig ricci on
Both>chkconfig pacemaker off
Both>chkconfig drbd on
Configuration Files:
- server1 = 10.1.1.1
- server2 = 10.1.1.2
- VIP = 10.1.1.3
#mysql is the drbd resource
resource mysql {
net {
# Automatic split brain recovery policies
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri call-pri-lost-after-sb;
}
syncer {
verify-alg sha1;
}
# Identifying the two nodes server1 and server2 which are the servernames
on server1 {
device /dev/drbd0; #drbd device mounted linked to disk
disk /dev/system/mysql_drbd; #physical location drbd data stored
address 10.1.1.1:7788; #IP:Port for communication by nodes
meta-disk internal; #Metadata stored within DRBD
}
on server2 {
device /dev/drbd0; #drbd device mounted linked to disk
disk /dev/system/mysql_drbd; #physical location drbd data stored
address 10.1.1.2:7788; #IP:Port for communication by nodes
meta-disk internal; #Metadata stored within DRBD
}
}
#All this does is identify the nodes server1 and server2 as well as defer fencing (STONITH) to pacemaker
<cluster config_version=”63″ name=”pacemaker1″>
<fence_daemon/>
<clusternodes>
<clusternode name=”server1″ nodeid=”1″>
<fence>
<method name=”pcmk-redirect”>
<device name=”pcmk” port=”node1″/>
</method>
</fence>
</clusternode>
<clusternode name=”server2″ nodeid=”2″>
<fence>
<method name=”pcmk-redirect”>
<device name=”pcmk” port=”node2″/>
</method>
</fence>
</clusternode>
</clusternodes>
<cman/>
<fencedevices>
<fencedevice agent=”fence_pcmk” name=”pcmk”/>
</fencedevices>
<rm>
<failoverdomains/>
<resources/>
</rm>
</cluster>
- Pacemaker configuration output – DO NOT EDIT THE FILE- this is a print out merely for comparison
<?Do not attempt to edit this directly, always use CRM!?>
<cib admin_epoch=”0″ cib-last-written=”Thu May 23 19:37:58 2013″ crm_feature_set=”3.0.7″ epoch=”182″ have-quorum=”1″ num_updates=”0″ update-client=”cibadmin” update-origin=”server2″ validate-with=”pacemaker-1.2″>
<configuration>
<crm_config>
<cluster_property_set id=”cib-bootstrap-options”>
<nvpair id=”cib-bootstrap-options-dc-version” name=”dc-version” value=”1.1.8-7.el6-394e906″/>
<nvpair id=”cib-bootstrap-options-cluster-infrastructure” name=”cluster-infrastructure” value=”cman”/>
<nvpair id=”cib-bootstrap-options-no-quorum-policy” name=”no-quorum-policy” value=”ignore”/>
<nvpair id=”cib-bootstrap-options-migration-threshold” name=”migration-threshold” value=”1″/>
<nvpair id=”cib-bootstrap-options-interval” name=”interval” value=”120s”/>
<nvpair id=”cib-bootstrap-options-last-lrm-refresh” name=”last-lrm-refresh” value=”1369046568″/>
<nvpair id=”cib-bootstrap-options-stonith-enabled” name=”stonith-enabled” value=”false”/>
<nvpair id=”cib-bootstrap-options-cluster-recheck-interval” name=”cluster-recheck-interval” value=”5s”/>
<nvpair id=”cib-bootstrap-options-failure-timeout” name=”failure-timeout” value=”30″/>
<nvpair id=”cib-bootstrap-options-resource-stickiness” name=”resource-stickiness” value=”51″/>
</cluster_property_set>
</crm_config>
<nodes>
<node id=”server1″ uname=”server1″/>
<node id=”server2″ uname=”server2″/>
</nodes>
<resources>
<master id=”ms_drbd_mysql”>
<meta_attributes id=”ms_drbd_mysql-meta_attributes”>
<nvpair id=”ms_drbd_mysql-meta_attributes-master-max” name=”master-max” value=”1″/>
<nvpair id=”ms_drbd_mysql-meta_attributes-master-node-max” name=”master-node-max” value=”1″/>
<nvpair id=”ms_drbd_mysql-meta_attributes-clone-max” name=”clone-max” value=”2″/>
<nvpair id=”ms_drbd_mysql-meta_attributes-clone-node-max” name=”clone-node-max” value=”1″/>
<nvpair id=”ms_drbd_mysql-meta_attributes-notify” name=”notify” value=”true”/>
</meta_attributes>
<primitive class=”ocf” id=”drbd_mysql” provider=”linbit” type=”drbd”>
<instance_attributes id=”drbd_mysql-instance_attributes”>
<nvpair id=”drbd_mysql-instance_attributes-drbd_resource” name=”drbd_resource” value=”mysql”/>
</instance_attributes>
<operations>
<op id=”drbd_mysql-monitor-29s” interval=”29s” name=”monitor” role=”Master”/>
<op id=”drbd_mysql-monitor-31s” interval=”31s” name=”monitor” role=”Slave”/>
</operations>
</primitive>
</master>
<group id=”g_mysql”>
<primitive class=”ocf” id=”fs_mysql” provider=”heartbeat” type=”Filesystem”>
<instance_attributes id=”fs_mysql-instance_attributes”>
<nvpair id=”fs_mysql-instance_attributes-device” name=”device” value=”/dev/drbd/by-res/mysql”/>
<nvpair id=”fs_mysql-instance_attributes-directory” name=”directory” value=”/var/lib/mysql”/>
<nvpair id=”fs_mysql-instance_attributes-fstype” name=”fstype” value=”ext4″/>
</instance_attributes>
</primitive>
<primitive class=”ocf” id=”ip_mysql” provider=”heartbeat” type=”IPaddr2″>
<instance_attributes id=”ip_mysql-instance_attributes”>
<nvpair id=”ip_mysql-instance_attributes-ip” name=”ip” value=”10.1.1.3″/>
<nvpair id=”ip_mysql-instance_attributes-nic” name=”nic” value=”eth0″/>
</instance_attributes>
</primitive>
<primitive class=”ocf” id=”p_mysql” provider=”heartbeat” type=”mysql”>
<instance_attributes id=”p_mysql-instance_attributes”>
<nvpair id=”p_mysql-instance_attributes-binary” name=”binary” value=”/usr/sbin/mysqld”/>
<nvpair id=”p_mysql-instance_attributes-config” name=”config” value=”/etc/my.cnf”/>
<nvpair id=”p_mysql-instance_attributes-datadir” name=”datadir” value=”/var/lib/mysql”/>
<nvpair id=”p_mysql-instance_attributes-pid” name=”pid” value=”/var/lib/mysql/mysql.pid”/>
<nvpair id=”p_mysql-instance_attributes-socket” name=”socket” value=”/var/lib/mysql/mysql.sock”/>
<nvpair id=”p_mysql-instance_attributes-user” name=”user” value=”mysql”/>
<nvpair id=”p_mysql-instance_attributes-group” name=”group” value=”mysql”/>
<nvpair id=”p_mysql-instance_attributes-additional_parameters” name=”additional_parameters” value=”–bind-
address=10.1.1.3 –user=mysql”/>
</instance_attributes>
<operations>
<op id=”p_mysql-start-0″ interval=”0″ name=”start” timeout=”30s”/>
<op id=”p_mysql-stop-0″ interval=”0″ name=”stop” timeout=”30s”/>
<op id=”p_mysql-monitor-10s” interval=”10s” name=”monitor” timeout=”30s”/>
</operations>
</primitive>
</group>
</resources>
<constraints>
<rsc_colocation id=”c_mysql_on_drbd” rsc=”g_mysql” score=”INFINITY” with-rsc=”ms_drbd_mysql” with-rsc-role=”Master”/>
<rsc_order first=”ms_drbd_mysql” first-action=”promote” id=”o_drbd_before_mysql” score=”INFINITY” then=”g_mysql” then-action=”start”/>
<rsc_location id=”location-p_mysql-server1-50″ node=”server1″ rsc=”p_mysql” score=”50″/>
</constraints>
<rsc_defaults>
<meta_attributes id=”rsc-options”>
<nvpair id=”rsc-options-resource-stickiness” name=”resource-stickiness” value=”100″/>
</meta_attributes>
</rsc_defaults>
</configuration>
- Corosync Config file – must be edited:
<?xml version=”1.0″?>
<?cluster config_version gets updated with every edit so that it knows it has a new version to load?>
<cluster config_version=”59″ name=”mysql”>
<fence_daemon/>
<?Here the two nodes are identified: server1 as node1 and server2 as node2?>
<clusternodes>
<clusternode name=”server1″ nodeid=”1″/>
<clusternode name=”server2″ nodeid=”2″/>
</clusternodes>
<?Allows Cluster to stay up without both sets of cluster components being up?>
<cman expected_votes=”1″ two_node=”1″/>
<?There is no fencing due to lack of resources?>
<fencedevices/>
<rm>
<failoverdomains/>
<resources/>
<?Here is where the mysql service is set up which includes drbd mounting information and tying mysql to the vitural IP?>
<?when the ‘recovery’ parameter is not defined it tries to restart it before failing over?>
<service autostart=”1″ name=”mysql” recovery=”relocate”>
<drbd name=”mysql” resource=”mysql”>
<fs device=”/dev/drbd0″ fstype=”ext4″ mountpoint=”/var/lib/mysql” name=”mysql” options =”noatime”/>
</drbd>
<ip address=”10.1.1.3″ monitor_link=”1″/>
<mysql config_file=”/etc/my.cnf” listen_address=”10.1.1.3″ name=”mysql”/>
</service>
</rm>
</cluster>
Good Luck!